水増しされていた中国の人口、「本当は10億人だった説」の衝撃──ハッキングでデータ流出 [中国ウオッチング]
ニューズウイーク日本語版
https://www.newsweekjapan.jp/stories/world/2023/03/post-101105.php
***************************
江沢民も胡錦濤も、中国経済の成長を支えるには外国資本の誘致が不可欠と考えていた。
だから中国には今でも10億人を超える巨大市場があり、その規模は何十年も先まで拡大を続けるし、安価な労働力もたっぷりあるという「神話」をつくり上げた。
データの改ざんは習近平(シー・チンピン)体制になってからも続いた。
「14億の民」という標語を振りかざせば、軍事面でも外交面でも虚勢を張り、諸外国を威圧することが可能だった。
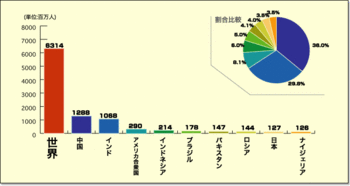
それでも中国は、22年の人口総数は約14億1000万人だったと今も主張し続けているが、ここ数年の人口データの修正から考えて、極めて疑わしい数字だ。
昨年6月、上海警察のデータベースがハッカー攻撃を受けた。
ハッキングで流出したデータセットには全国民の個人識別情報が含まれていた様だ。
中国の本当の人口は14億でも12億8000万でもなく、せいぜい10億人程度という可能性がある。
*************************
実は中国の人口は世界一ではなかったという話ですね。
インドに続いて2位だった。
まあ、あり得ることでしょうけど、ちゃんと人数を把握していた事に、むしろ驚きます。
https://www.newsweekjapan.jp/stories/world/2023/03/post-101105.php
***************************
江沢民も胡錦濤も、中国経済の成長を支えるには外国資本の誘致が不可欠と考えていた。
だから中国には今でも10億人を超える巨大市場があり、その規模は何十年も先まで拡大を続けるし、安価な労働力もたっぷりあるという「神話」をつくり上げた。
データの改ざんは習近平(シー・チンピン)体制になってからも続いた。
「14億の民」という標語を振りかざせば、軍事面でも外交面でも虚勢を張り、諸外国を威圧することが可能だった。
それでも中国は、22年の人口総数は約14億1000万人だったと今も主張し続けているが、ここ数年の人口データの修正から考えて、極めて疑わしい数字だ。
昨年6月、上海警察のデータベースがハッカー攻撃を受けた。
ハッキングで流出したデータセットには全国民の個人識別情報が含まれていた様だ。
中国の本当の人口は14億でも12億8000万でもなく、せいぜい10億人程度という可能性がある。
*************************
実は中国の人口は世界一ではなかったという話ですね。
インドに続いて2位だった。
まあ、あり得ることでしょうけど、ちゃんと人数を把握していた事に、むしろ驚きます。
Open AIが「GPT-4」発表──マルチモーダル化、文章・画像を併用した質問に対応 [サイエンス]
ニューズウイーク日本語版
https://www.newsweekjapan.jp/stories/technology/2023/03/open-aigpt-4.php
**************************
まずは有料サービス「ChatGPT Plus」の利用者や、API経由で開発者向けに提供する。
デモ動画: https://twitter.com/i/status/1635687373060317185
GPT-4はマルチモーダル化も果たした。
そのため画像と文章を併用した難しい質問も扱える。
例えば画像を入力した上で「この画像は何が面白い?」と質問すると回答する。
前バージョンはテキストのみに対応。今後、動画、音声といったコンテンツへの対応が期待される。
またGPT-4は「許可されないコンテンツの生成に対応してしまう可能性」がGPT-3.5と比較して82%低く、「医療や自傷行為」といったセンシティブな内容を含むリクエストにOpenAIのポリシーに則して回答する確率は29%増えたという。
********************
最近流行りの、チャットGTPってどうなんでしょう???
余り興味がわかないので、突っ込んでいません。
結局は、知識データベースを組み合わせて文章等を構築するんでしょうか?。
個人的には、「人工知能」なんて偉そうで、なんだか”おこがましくて”好きになれません。
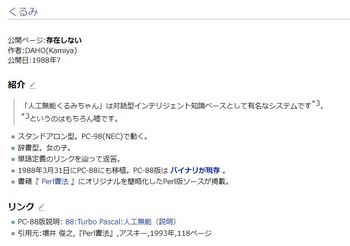
そういえば、30年以上前の日本国内のパソコン通信では、「人口無能 くるみちゃん」ってプログラムが有りました。
聞くところに寄ると、基本的な構造は「自己学習機能」を持った辞書データベースで、なにか質問をすると、辞書の中から質問に適した内容を探し出して、会話の様に構成し答えるように成っていたらしいです。
会話が途切れると、辞書の中から自分の得意分野に関する質問を、会話の相手に投げかけてくるなど、とても良くできていた様でした。
基本となる辞書は最初はまっさらなのですが、会話を繰り返していくうちに、例えば「パソコン」に知見の高い人が相手で話を繰り返すと、「自己学習機能」が働いてその方向に強い辞書に自己学習していくので、「人工無脳」にも個性が出てくるそうです。
過去のパソコン通信の時代に存在したソフトなのですが、これをパソコン通信のサーバーに仕込んでおくと、チャットの相手は気が付かないで、人だと思って話し込んでしまったなんて話もありました。
そう考えてみると、当時の日本のパソコンの文化は結構進んでいたのだなぁ・・と感慨深いですね。
人工無能: https://w.atwiki.jp/munou/pages/1.html
ゲームの世界でいうと、セガサターンの「人面魚」も面白かった。
動画; 人面魚
https://youtu.be/Mh4NwAIZYdQ
https://www.newsweekjapan.jp/stories/technology/2023/03/open-aigpt-4.php
**************************
まずは有料サービス「ChatGPT Plus」の利用者や、API経由で開発者向けに提供する。
デモ動画: https://twitter.com/i/status/1635687373060317185
GPT-4はマルチモーダル化も果たした。
そのため画像と文章を併用した難しい質問も扱える。
例えば画像を入力した上で「この画像は何が面白い?」と質問すると回答する。
前バージョンはテキストのみに対応。今後、動画、音声といったコンテンツへの対応が期待される。
またGPT-4は「許可されないコンテンツの生成に対応してしまう可能性」がGPT-3.5と比較して82%低く、「医療や自傷行為」といったセンシティブな内容を含むリクエストにOpenAIのポリシーに則して回答する確率は29%増えたという。
********************
最近流行りの、チャットGTPってどうなんでしょう???
余り興味がわかないので、突っ込んでいません。
結局は、知識データベースを組み合わせて文章等を構築するんでしょうか?。
個人的には、「人工知能」なんて偉そうで、なんだか”おこがましくて”好きになれません。
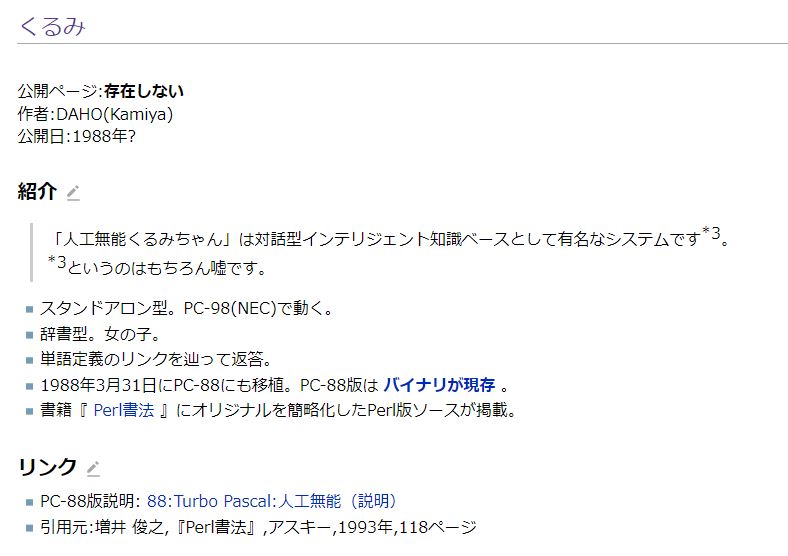
そういえば、30年以上前の日本国内のパソコン通信では、「人口無能 くるみちゃん」ってプログラムが有りました。
聞くところに寄ると、基本的な構造は「自己学習機能」を持った辞書データベースで、なにか質問をすると、辞書の中から質問に適した内容を探し出して、会話の様に構成し答えるように成っていたらしいです。
会話が途切れると、辞書の中から自分の得意分野に関する質問を、会話の相手に投げかけてくるなど、とても良くできていた様でした。
基本となる辞書は最初はまっさらなのですが、会話を繰り返していくうちに、例えば「パソコン」に知見の高い人が相手で話を繰り返すと、「自己学習機能」が働いてその方向に強い辞書に自己学習していくので、「人工無脳」にも個性が出てくるそうです。
過去のパソコン通信の時代に存在したソフトなのですが、これをパソコン通信のサーバーに仕込んでおくと、チャットの相手は気が付かないで、人だと思って話し込んでしまったなんて話もありました。
そう考えてみると、当時の日本のパソコンの文化は結構進んでいたのだなぁ・・と感慨深いですね。
人工無能: https://w.atwiki.jp/munou/pages/1.html
ゲームの世界でいうと、セガサターンの「人面魚」も面白かった。
動画; 人面魚
https://youtu.be/Mh4NwAIZYdQ



